► 文 观察者网专栏作者 潘禺
“当我想到我认识的十个最聪明的物理学家时,我会说,其中一半人确信量子计算将成为自切片面包以来最好的东西。这将是21世纪的技术。另一半人则确信,即使你能建造一个量子计算机(你肯定做不到),它也永远不会比你的笔记本电脑更有用。在有史以来最有用技术和完全无用之间存在巨大的差距……”

“炒作是真的吗?量子计算将改变一切,还是这真的被过度夸大了,这更多是一个基础科学问题,对于美国来说,这是一个极其重要的问题。”以上这些话,来自美国国防部高级研究计划局(DARPA)今年8月公布的一个视频。
在国内媒体上,中国公众也已经听到了太多关于量子计算的美好承诺,但其中绝大部分都是空头支票。如果能够开发出能容错的量子计算机,对各种科学和工业应用都可能产生革命性的影响——这一假设尚未被证明,至少有两个重要原因。
一个原因是,尽管已经为量子计算机提出了一些算法和应用,但在大多数情况下,尚未完成与现实世界中使用的最佳经典替代方案进行严格比较。另一个原因是,尚不清楚何时或是否可以建造一个商用量子计算机,也就是其计算价值超过其成本,特别是对于需要容错的应用。容错的商用量子计算机,复杂性可能超过传统超级计算机。因此,要证明商用规模设计是可行的,所有必要的组件和子系统都能以所需规格生产,并能成功集成,这非常困难。
商用量子计算机真的可能吗?美国政府现在正努力审视这个问题了。
美国政府的怀疑
2024年7月,DARPA宣布了量子基准测试倡议(Quantum Benchmarking Initiative,简称QBI),针对那些认为自己有望开发出容错的商用量子计算机的公司。前面提到的视频,就来自QBI的概述。
所谓量子基准测试,就是要定量衡量量子计算的关键进展。对量子计算的未来承诺,往往是未经证实的,那有什么基准能预测明天的量子计算机是否真正具有革命性?一个关键指标就是,估计给定基准性能水平所需的硬件资源。
早在多年前,DARPA就启动了量子基准测试,在第一阶段,有8个跨学科团队编制了200多个潜在应用,从中创建了20个候选基准,用量子计算机解决这些困难的计算任务,具备经济效用并可以量化。
在下一阶段,DARPA选择了三大类特定基准,进行详细研究,分别是化学、材料科学和非线性微分方程,在乐观的承诺中,这些都是量子计算具备优势,可以更高效解决的问题领域。DARPA选择了五个团队,根据严格、以效用为驱动的标准完善这些选定的基准,评估现实世界的效用,并创建工具以估计在现实量子硬件上运行应用程序端到端实例所需的资源和性能。结果表明,量子计算机为某些化学、材料科学应用提供优势存在合理性,但目前尚不清楚是否能够在非线性微分方程应用中实现任何优势。
这次最新的倡议,名义上,DARPA声称是要与美国和世界各地的量子计算公司合作,确定哪些方法最有可能成功,并加以推进,但事实上,DARPA是想要重审形形色色的量子计算项目,检验方法和技术的成熟度。
DARPA想要回答两个非常基本的问题。第一个问题是“如果我有一个真正强大的量子计算机。我能用它做什么?”第二个是“是否有商业公司、学术团体或任何团体有在近期内真正构建那种机器的路径?”
按照DARPA的说法,被QBI资金选中的执行者,要专注于开发并描述有真正价值的量子计算机,也就是其计算价值超过其成本,并且在近期内有实现的合理途径。DARPA的意思就是你们别玩虚的概念,要给出健全的研究和开发计划,提供已证明效用的应用和算法,验证并确认概念可以按设计构建并按预期运行,总之一句话,要对你们的项目做核实和评估。
而评估一个量子计算公司,看看他们的方法是否真的站得住脚,是否真的能在近期内制造出商用的机器,这是非常困难的。所以DARPA将建立一个世界级的验证和确认团队,邀请美国和外国公司参与进来。
“如果真有可能构建这样一个(量子计算机),而且它真的可能具有变革性,那对于政策制定有着深远的影响。如果结果如我们许多人怀疑的那样,真的不可能,它真的不会做一些有用的事情,或者没有路径,我们也需要知道这一点,这样我们就可以更好地规划我们的基础研究资金。因此,DARPA正在启动一个名为量子基准测试倡议的项目。这是一个由DARPA牵头的新的重大政府计划,目的是尝试做到这一点。”
负责QBI的Joe Altepeter博士直言不讳地表示:“我们的初始立场是怀疑”。具体来说,就是怀疑是否可能建造一个完全容错的量子计算机,拥有足够数量的逻辑量子比特。“我们会走进房间说,‘我们相当确定你正在做的事情不会成功。’我会带上一小群科学家和工程师,我们会听取你的证据,并利用我们自己的分析进行双重和三重检查。如果我们确信你正在开发的技术通过了检查,你发现了一些重大的东西,我们会告诉政府的其他人,并成为你方法的坚定支持者。”
量子霸权的争议
2019年10月,谷歌宣布通过其53个量子比特的Sycamore处理器实现了量子霸权。在执行随机电路采样的计算问题上,与经典超级计算机相比,谷歌宣称达到了以200秒对10000年的优势。特朗普的女儿伊万卡·特朗普(Ivanka Trump)当时在社交媒体上对谷歌在量子计算领域取得的成就表示祝贺,并称“美国实现了量子霸权”。
然而,IBM等公司对此表示质疑,IBM认为使用经典超级计算机完成相同任务所需的时间可以从谷歌声称的10000年降低到仅需2.5天,阿里巴巴也曾发表声明否定谷歌声称的量子霸权优势,表示可将所需时间从10000年降低到20天内。
量子计算机会比今天的计算机快多少倍,这是一个很自然的问题。不要被谷歌的说辞迷惑,首先要明白,谷歌或任何其他公司声称他们已经实现了量子加速,都只是针对特定的、深奥的基准测试。他们的量子计算机既不能在通常的任务中胜过传统计算机,也不能在破解密码、模拟化学等有实际应用的特定任务中胜过传统计算机。
而即便在“人为指定的赛道”中,所谓量子霸权(或量子加速)也是难以证实的。
解决一个任务的运行时间取决于算法,通常会随着输入数据位数n的增加而增加,形成一个函数关系。比如,一个任务采用一个经典算法需要的步骤数随着n指数增长,而用量子计算机,以某种算法,步骤数只增长为n^2就能解决,在这种情况下,对于小n,用量子计算机解决问题实际上会比用经典方法解决问题更慢、更昂贵。只有当n增长时,量子加速才会首次出现,然后最终占据优势。
但我们怎么知道经典计算机就没有算法捷径呢?这个问题是量子算法研究的核心,通常困难不在于证明量子计算机可以快速完成某件事,而是令人信服地论证经典计算机不能。正如著名的难题P与NP问题,想要给出这样的论证是非常困难的。而在过去的几十年里,当发现具有类似性能的经典算法时,之前推测的量子加速已经反复消失。这也就是开头所说的两个重要原因中的第一个。
要讲清楚另一个重要原因,理解构建量子计算机的困难,就要先从更基本的原理讲起。
为什么量子计算需要纠错
在经典计算机中,信息以可检索的比特形式存储,二进制编码为0或1。在量子计算机中,基本粒子处于叠加态,一个n量子比特的量子计算机可以表示2^n个可能的状态,这允许量子计算机在一次操作中处理大量数据,使得量子算法在解决某些问题时,具有潜在的指数级加速。
叠加并不能简单理解为“同时”,不是说量子比特可以“同时是0和1”,而经典比特只能是其中之一。如果你看到一个所有可能答案的等概率叠加,并读取一个随机答案,这显然没有意义。
叠加的真实含义,可以表示为0态和1态的“线性组合”,也就是∣ψ⟩=α∣0⟩+β∣1⟩,其中α和β是复数,称为概率振幅(probability amplitudes),这些振幅的绝对值的平方给出了当量子比特被测量时,系统塌缩到相应状态的概率。某个结果的振幅越接近零,看到那个结果的机会就越小。
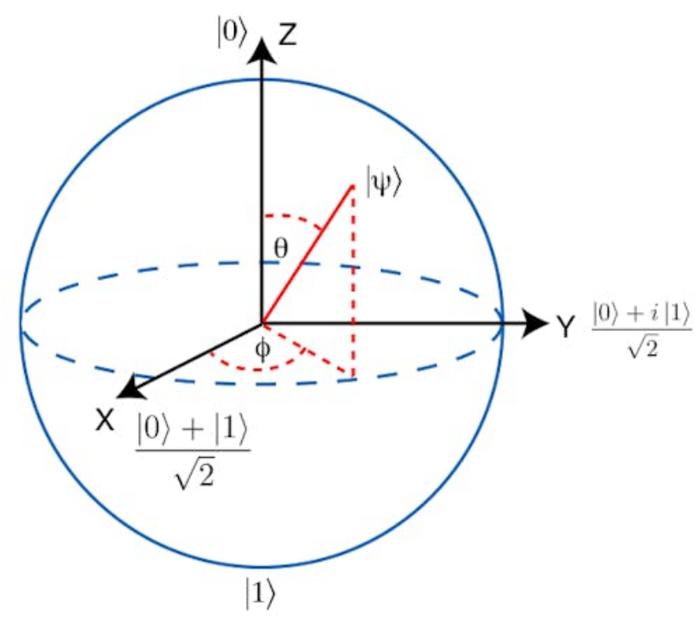
量子比特的可能状态|ψ⟩可以表示为Bloch球面上的一个点
这意味着,可以把不同倍数的状态加在一起。每个量子比特都可以与机器中的其他量子比特纠缠。建设性的干涉,会增加某个结果的可能性,而破坏性的干涉,互相抵消,会让振幅为零,相应的结果就从未被观察到。设计量子计算机算法的目标是编排一种建设性和破坏性干涉的模式,以便对于每个错误答案,其振幅的贡献相互抵消,而对于正确答案,贡献则相互加强。
只有这一切都安排好,观察时才会以很大的概率看到正确答案。要做到这一点而不提前知道答案,并且比你用经典计算机做到的要快,正是棘手的地方。
更困难的问题是退相干。量子计算机与其环境之间的相互作用,不管是热振动、宇宙射线、电磁干扰还是其它噪声源,可能导致量子比特过早被“测量”,它们坍缩成0或1单一值的经典比特。
人们从一开始就不清楚,量子计算机提供的指数级加速是否会因保护系统免于崩溃所需的指数级复杂性而被抵消。叠加态非常脆弱,以至于单个量子比特与其周围环境中分子的随机相互作用可能导致整个纠缠量子比特网络脱链或崩溃。随着每个量子比特转化为数字化经典比特0或1,正在进行的计算就被破坏。
这就需要纠错。在经典计算机中,纠错通过在系统中设计大量的冗余实现。纠错算法比较多份输出,选择最常见的答案,并将其余数据作为噪声丢弃。但不能对量子计算机这样做,因为尝试直接比较量子比特会使程序崩溃。因此,必须设计并实现一个只测量错误而不是数据的算法,从而保留包含正确答案的叠加态。一个在20世纪90年代中期提出的纠错方案,巧妙地将量子计算中的每个量子比特编码到几十个甚至数千个物理量子比特的集体状态中,大量的量子位专门用于纠错。
但纠错技术本身会引入错误。当然,从理论上讲(实际上并没做到),可以在不需要100%精度的情况下纠正新的错误,允许小的背景噪声在计算进行时污染计算。这意味着希望还没有完全破灭。
把“容错”算法植入量子电路,目前可以合理地控制十来个量子比特,但这离至少数千个量子比特、有用的商用量子计算机过于遥远。当你读到关于50或60个物理量子比特的最新实验时,重要的是,要明白这些量子比特没有纠错。
世界上最大的量子计算机(就量子位而言)是IBM的Osprey,拥有433个量子位。但即使有200万个量子位,一些量子化学计算可能需要一个世纪。据一篇最新的论文估计,在8小时内破解最先进的密码将需要2000万个量子位,这已经很乐观了,比之前估计的10亿个量子位要少得多。
对中国的启示
任何一个时髦的科技领域,随着大量金钱的涌入,都有可能出现骗子。在过去20年里,至少有数十亿美元投入到量子计算,但公共媒体甚至没有讲清楚这个领域中的大量基本常识。
新闻里除了不会告诉你“量子比特没有纠错”,还有大量的欺骗性话术和概念混淆。比如,量子模拟和量子计算的概念就被混淆。新闻里会夸耀加拿大的D-Wave是全球第一家成功实现商业化的量子计算公司,拥有独家的退火技术量子计算,客户包括洛克希德·马丁、大众、NASA、谷歌等。

但D-Wave是一台纯粹模拟机器,旨在解决特定的优化问题,它不是数字的,也不是纠错的,也不是容错的。
数字和模拟的区别是什么呢?假设你想要模拟全球气候变化。一种方法是编写一个数学模型,然后在数字计算机上解方程。这通常是气候科学家所做的。另一种方法是尝试在可控实验中模拟地球气候的某些方面。可以创建一个遵守与试图模拟的系统相同运动定律的简单物理系统——例如,在罐子中混合氮气、氧气和氢气。罐子内部发生的事情是一次真实世界的计算,它告诉你,在某些条件下大气湍流的情况。
量子模拟器本质也是用一个可控物理系统来模拟另一个。由于模拟演变没有数字化,软件无法进行错误校正,模拟设备必须保持量子叠加态足够长的时间,其难点与通用的量子计算机不同。
中国也在量子计算机领域取得了显著成果,见诸新闻报道的就有“九章”、“祖冲之”、“本源悟空”等型号,代表光量子和超导两条技术路线。中国在量子计算领域的科研进展当然令人鼓舞,但经过前面的分析不难理解,去比较中国是全球第二个还是第几个实现了“量子霸权”或“量子优越性”的国家,本身就陷入了谷歌开启的无聊炒作。
《自然》杂志2023年5月发表的一篇文章指出:“事实上,所有的量子计算机都可以用糟糕来形容,数十年的研究尚未产生一台能够启动承诺中的计算革命的机器……到目前为止,有充分的理由对量子计算的前景持怀疑态度。量子专家还没有实现任何真正有用且不能使用经典计算机完成的事情。”

莱布尼茨超级计算中心的量子计算机
另一个重要问题也被新闻媒体所忽略。数据的存储、取出是横在量子计算机前进道路上的又一座难以逾越的大山,并且存在原理性障碍,很难通过工程技术手段得到解决。计算机的算力不只取决于中央处理器CPU的性能,也与内存的容量和内存联接CPU的带宽有关。对于诸如AI等许多实际问题,内存带宽更是决定性的,目前英伟达的GPU H100的内存带宽已达3TB/s。
受物理原理限制,高速、长时、大容量量子存储器难以实现,所以量子计算机还需依赖于传统的电子存储器,这就必然增添了量子信息与电子信息之间来回倒换的许多麻烦,量子加速会在这个过程中大打折扣,甚至总体可能得不偿失。
这次美国的DARPA与美国能源部科学办公室、伊利诺伊州、美国空军研究实验室的量子科学家和工程师合作,进行量子基准测试倡议,其实就是追问两个问题的答案:量子计算机能够实现标准计算机无法完成的事情吗?构建一个容错的商用量子计算机可能吗?
一位在美国的华裔学者告诉心智观察所:“这个动作在DARPA的历史上是罕见的,我不记得有什么开创性、革命性的技术面临过如此特别待遇。”
DARPA表示,当量子技术看似无处不在、无所不包时,他们正试图从炒作中提炼出真正的价值,凭借健康的怀疑态度、科学严谨性以及行业和学术专家的知识。
这个动作挺值得中国借鉴,无论DARPA会做得怎样,中国也可以用自己的方式,把这种“健康的怀疑态度”用于重新审视自己的科研项目,不限于量子计算。科研项目的学术成果与真正的产业应用是有很大距离的,甚至可能是完全不同的模式,未必都能走通,这就需要将真正的价值“从炒作中提炼”。
“量子计算如果仅仅在学术界进行讨论,资金投入给人脑,那么任何产出大致都可以接受,毕竟人力资源的投入相对硬资产的投入要小而可控性强,但是一旦进行产业化前期的验证性资本投入,就需要在更多维度上对项目进行可行性考核。”另一位业内学者向心智观察所表示。
他这样解释DARPA的这一动作:“DARPA对于几十年来在量子计算持续不断地硬资产投入和各种缺少衡量指标性的炒作显得不耐烦,因此这次DARPA直接强硬打断所有量子计算专家的话,告诉他们,不要告诉我你做了什么,让我们来先制定一个评判标准体系,然后你来告诉我,你做的能够符合标准体系的哪一条。”
不久前,中国半导体行业协会理事长、长江存储董事长陈南翔在采访中表示,过去在发展集成电路的过程中,中国走了很长一段时间的“弯路”。本质上,中国想要发展的是一种芯片产业,但过去这件事交给大学、研究院和科学院,最终获得的是一种更具学术性的成果。
陈南翔强调,这是两种完全不同的路径,中国现在需要的是一种产业,需要创新的产业、服务和商业模式,最终转变为经济的商业价值。“我认为,在花了很长一段时间的摸索之后,无论是从政策的主导者,还是产业利益的相关方,终于明白了。”
“不能说我们已经找到了产业发展的最佳模式,但起码,我们已经知道了什么样的模式是注定要失败的。在长时间试错后,现在我们可以相信,在未来集成电路产业的发展中,一定正孕育着一个巨大的成功模式。大家拭目以待。”
陈南翔讲清楚了发展产业与取得学术成果的不同,值得深思。科研并非一条只需向前看的坦途,总结走过的弯路,中国也需要DARPA这样回头看的动作,努力审视科研成果的真正价值,这很重要。
来源|观察者网